
Pyppeteer Tutorial: Crawling by intercepting response
2018-12-30
Intro
Pyppeteer is a Python-porting of Puppeteer. It's a perfect tool for web crawling. Most articles on pyppeteer crawling are focusing on extracting data from the rendered pages. In this article, I'll show you another approach: crawling by intercepting web requests from the page.
The Process of webpage rendering
When we open a new webpage in browser, if it is a SPA (Single Page Application), the browser will first load the code of application framework. When the framework loaded, the page will make another request to fetch the data, and then rendering it on the page.
The whole process is as below:
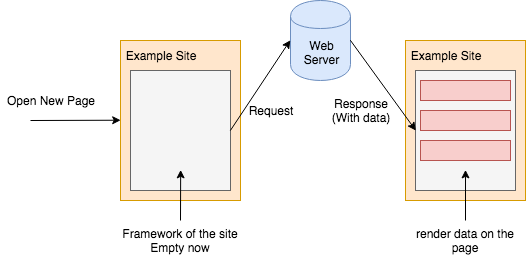
In many tutorials, they extracts data from the rendered page, using xpath, querySelector or BeautifulSoup. This approach is as below:
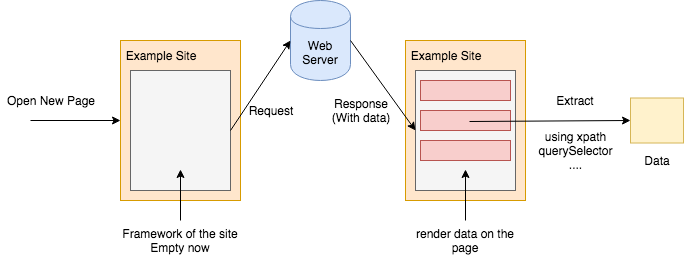
In this blog, we extract data by intercepting requests, which is as below:
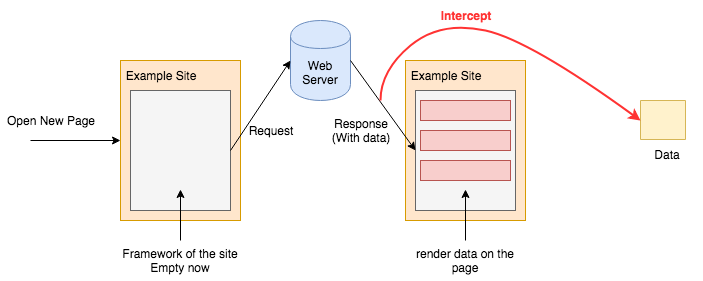
The data is usually formatted in JSON, which is easy to parse.
Pyppeteer Page Class
In pyppeter, a page class is corresponding to a page in the browser.
We will hook on the reponse event from EventEmitter:
async def interceptResponse(response): # your parsing logic ... browser = await launch(headless=False, devtools=True) page = await browser.newPage() page.on('response', lambda response: asyncio.ensure_future(interceptResponse(response)))
The type of response is pyppeteer.network_manager.Response. It has many usefull fields:
| Field | Type | Comment |
|---|---|---|
| headers | dict | dictionary of HTTP headers of this response |
| json | dict | Get JSON representation of response body. |
| ok | bool | Return bool whether this request is successful (200-299) or not. |
| request | Request | Get matching Request object. |
| status | int | Status code of the response. |
| text | str | Get text representation of response body. |
| url | str | URL of the response. |
Among abrove:
- json is data we need, in type of Python dict!! We can use it directly!!
- we can use url to tell filter the response we need
A example of interceptResponse may as below:
def url_feed_parse_filter(response): json_data = response.data # parse logic for feed response # ... async def interceptResponse(response): url = response.url if not response.ok: print('request %s failed' % url) return if url == URL_FILTER_FEED: url_feed_parse_filter(response)
Conclusion
In this blog, I introduce a approach of crawling data by intercepting response.
The advantage of this approach is that instead of extract data from rendered page, we directly parse the API response JSON, it's like we continue developing the application.