
使用 Scrapy 和 DeltaFetch 进行增量爬取(翻译)
2019-03-25
前言
本文的原作者是 Valdir Stumm Jr,文章源链接为 INCREMENTAL CRAWLS WITH SCRAPY AND DELTAFETCH,我将其翻译成中文。
欢迎来到 Scrapy 专业窍门!在本月的专栏中,我们将分享一些技巧,来帮助你加快 web 爬取活动的速度。
作为 Scrapy 的主要维护者,你能想到的每一个坑我们都遇到过,所以不用担心,你们有强大的支撑。
欢迎关注原作者的 Twitter 和 Facebook,欢迎交流。

Scrapy 被设计成可扩展的、组件间松耦合的框架。你可以通过 middleware 和 pipeline 很容易地扩展 Scrapy 的功能。
这使得 Scrapy 社区能够更容易地开发新插件来改进现有功能,而不需要修改 Scrapy 本身。
在本文中,我们将展示如何通过 DeltaFetch 插件来改善爬虫。
增量爬取
我们开发的一些爬虫被设计成只抓取一次性的数据。另一方面,许多爬虫程序必须定期运行,以保持我们的数据集是最新的。
在许多这些周期性的爬虫中,我们只关心自上次爬取后的新页面。
例如,我们有一个爬虫,它从许多在线媒体上爬取大量文章。爬虫每天执行一次,他们首先从预先定好的索引页爬取文章的 urls。然后他们从每篇文章中抽取出标题、作者、日期、内容。
这种方法经常导致许多重复的结果,并且每次运行爬虫程序时请求的数量都会增加。
幸运的是,我们不是第一个遇到这个问题的人。
社区中已经有了解决方案:scrapy-deltafetch plugin。你可以使用这个插件进行增量爬取。
你可以使用这个插件进行增量爬取。
DeltaFetch 的主要目标是避免重复爬取那些之前已经被爬取的页面,即使是刚刚执行过的,也不会再重复爬取。
它只会去请求之前没有提取过 items 的页面,这些页面包括 start_urls 中的 url,以及通过 start_requests 产生的请求。
DeltaFetch 的工作原理是拦截怕从回调中每个 Item 和 Request 对象。
对于 Items,他计算对应的请求标识(即 fingerprint),并将它保存在一个本地的数据库中。
对于 Request,Deltafetch 计算 fingerprint,并抛弃那些已经在数据库中的请求。
下面我们来看如何给 Scrapy 爬虫设置 Deltafetch。
DeltaFetch 安装
首先通过 pip 安装 DeltaFetch:
$ pip install scrapy-deltafetch
之后需要在项目的 settings.py 进行如下设置:
SPIDER_MIDDLEWARES = {
'scrapy_deltafetch.DeltaFetch': 100,
}
DELTAFETCH_ENABLED = True
DeltaFetch 实战
这个爬虫项目有一个爬取 books.toscrape.com 的爬虫。它访问所有列表页,并访问每个图书详情页,来爬取图书信息(标题、描述、分类)。
这个爬虫每天执行一次,来抓取分类下新的图书。
不需要重新访问已经被抓取的图书页面,因为爬虫收集的数据通常不会更改。
为了实战 DeltaFetch,现将这个项目 Clone 下来,其中 DeltaFetch 已经在 settings.py 中启用了。
运行下面指令:
$ scrapy crawl toscrape
等待一回儿直到完成后,看看 Scrapy 最后的日志:
2016-07-19 10:17:53 [scrapy] INFO: Dumping Scrapy stats:
{
'deltafetch/stored': 1000,
...
'downloader/request_count': 1051,
...
'item_scraped_count': 1000,
}
其中:
- 你会看到爬虫发出了 1-51 个请求,爬取到 1000 个项目
- DeltaFetch 存取了 1000 个请求 fingerprints
- 这意味着只有 51 个页面请求没有生成 items,因此它们会在下一次重新访问
现在,再次访问,你会看到下列消息:
2016-07-19 10:47:10 [toscrape] INFO: Ignoring already visited:
<GET http://books.toscrape.com/....../index.html>
在统计中你会看到,1000 个请求由于之前已经被爬过,因此被跳过。
现在爬虫没有抽取 items,并且实际只发出了 51 个请求,所有这些都可以列出以前没有爬过的页面:
2016-07-19 10:47:10 [scrapy] INFO: Dumping Scrapy stats:
{
'deltafetch/skipped': 1000,
...
'downloader/request_count': 51,
}
修改数据库 key
DeltaFetch 默认使用请求 fingerprint 来分辨请求。
fingerprint 是基于 URL、HTTP 方法和请求体计算出来的一个哈希值。
有些网站存在多个 URL 对应同一个数据的情况。例如,电商网站可能多个 url 对应同一个产品:
- www.example.com/product?id=123
- www.example.com/deals?id=123
- www.example.com/category/keyboards?id=123
- www.example.com/category/gaming?id=123
请求 fingerprints 不适合这种情况。在这种情况下,可以使用产品的 id 作为 DeltaFetch key。
DeltaFetch 允许我们在初始化请求时通过传入一个名为 deltafetch_key meta 参数来自定义 key:
from w3lib.url import url_query_parameter ... def parse(self, response): ... for product_url in response.css('a.product_listing'): yield Request( product_url, meta={'deltafetch_key': url_query_parameter(product_url, 'id')}, callback=self.parse_product_page ) ...
这样,DeltaFetch 就会忽略不同 URL 的重复页面请求了。
重置 DeltaFetch
如果你想重新爬取页面,你可以重置 DeltaFetch 缓存,通过向爬虫传入 deltafetch_reset 参数:
$ scrapy crawl example -a deltafetch_reset=1
在 Scrapy Cloud 中使用 DeltaFetch
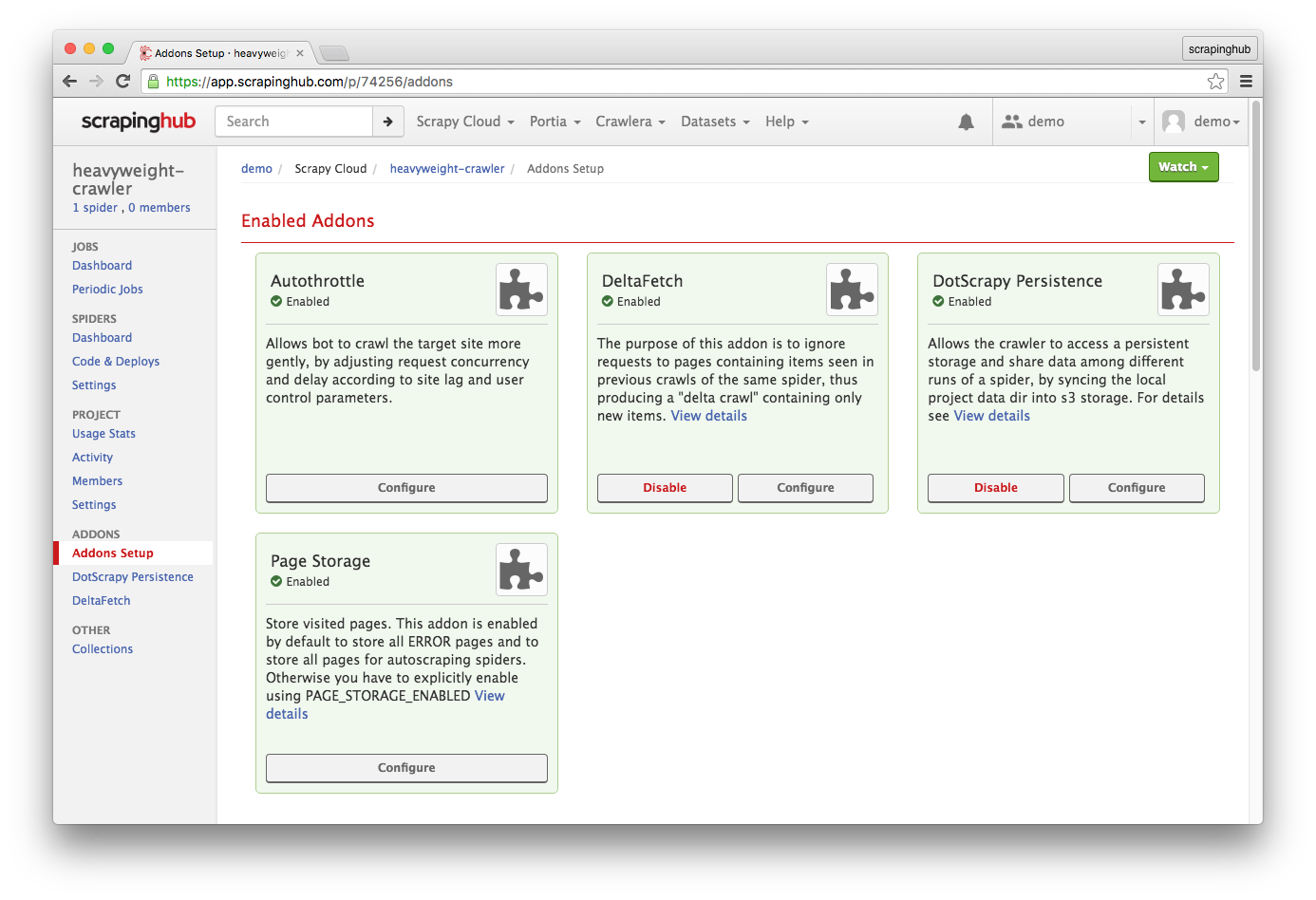
你还可以在运行在 Scrapy Cloud 上的爬虫中使用 DeltaFetch。
只需要在项目扩展页面启用 DeltaFetch 和 DotScrapy Persistence 扩展。
后一个插件允许你的插件访问 .scrapy 目录,DeltaFetch 会把数据库存储在那里。
Deltafetch 在我们前面看到的情况下非常方便。
需要记住的是,Deltafetch 之避免对已经爬取产生过 items 的页面发送重复请求。
如果页面没有爬取出 item,那么每次运行爬虫时都会爬取这个页面。
更多信息请参阅项目首页:http://github.com/scrapy-plugins/scrapy-deltafetch
小结
你可以在 scrapy-plugins 上找到很多有趣的 Scrapy 插件。
你也可以将自己的插件向社区进行贡献。
如果你有问题或者有感兴趣的话题,请在 Twitter 的 @scrapinghub 账号下留言。